
Можно использовать множество показателей того, обучилась программа или нет для более эффективного выполнения своих задач. В задачах обучения с учителем многие показатели эффективности измеряют число ошибок прогнозирования. Есть две основных причины ошибок прогнозирования — это смещение модели и ее дисперсия.
Предположим, что у вас есть много обучающих выборок, которые являются уникальными, но одинаково представляют генеральную совокупность.
Модель с большим смещением будет производить одинаковые ошибки для входа, независимо от обучающего множества, на котором происходило обучение. Модель смещает свои собственные предположения о реальных отношениях из-за связей, имеющихся в обучающих данных.
Модель с большой дисперсией, наоборот, будет производить различные ошибки для входа в зависимости от обучающего множества, на котором она училась.
Модель с большим смещением не гибкая, а модель с высокой дисперсией может быть, напротив, настолько гибкой, что смоделирует шум в обучающем множестве. То есть, модель с высокой дисперсией «переподгоняет» (overfit) обучающие данные, в то время как модель с большим смещением недостаточно точно подгоняет обучающие данные.
Можно представить смещение и дисперсию как дротики, брошенные в мишень. Каждый дротик аналогичен предсказанию, использующему другой набор данных.
Модель с большим смещением, но малой дисперсией будет метать дротики, которые далеки от центра мишени, но плотно кучкуются (кластеризуются). Модель с большим смещением и высокой дисперсией будет бросать дротики по всей площади мишени . Дротики будут далеки от центра и друг от друга.
Модель с небольшим смещением и большой дисперсией, будет метать дротики близко к «яблочку», но с плохой кластеризацией.
Наконец, модель с небольшими смещением и дисперсией будет метать дротики, которые будут плотно группироваться вокруг «яблочка».
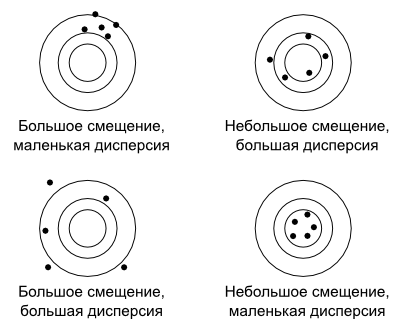
В идеале, построенная модель должна иметь небольшие и смещение и дисперсию, но усилия по снижению одного показателя часто будут приводить к увеличению другого. Это называется компромиссом между смещением и дисперсией.
Задачи обучения без учителя не имеют сигнала ошибки измерения, вместо этого показатели эффективности измеряют некоторые параметры структуры, обнаруженной в данных.
Большинство показателей эффективности могут быть вычислены только для определенного типа задач.
Системы машинного обучения должны оцениваться с использованием показателей эффективности, которые представляют собой оценки, связанные с созданием ошибки в реальном мире. Хотя это может показаться очевидным, следующий пример описывает использование измерения эффективности, которая подходит для выполнения этой задачи в целом, а не для ее конкретного приложения.
Рассмотрим задачу классификации из области медицины, в которой система машинного обучения наблюдает за опухолями и должна предсказывать, является опухоль доброкачественной или же злокачественной. Погрешность, или доля случаев, которые были классифицированы правильно, интуитивно является мерой эффективности программы. В то время, как точность измеряет эффективность программы, она не делает различий между злокачественными опухолями, которые были классифицированы как доброкачественные и доброкачественные опухоли, которые были классифицированы как злокачественные. В некоторых случаях, оценки для разных типов ошибок могут быть одинаковыми. Однако, в этой задаче, не определение злокачественной опухоли, вероятно, будет более серьезной ошибкой, чем ошибочная классификация доброкачественной опухоли, как злокачественной.
Мы можем измерить каждый из возможных исходов прогнозирования, чтобы создать различную точку зрения на эффективность классификатора. Когда система правильно классифицирует опухоль как злокачественную, предсказание называют истинным положительным (true positive). Когда система не правильно классифицирует доброкачественную опухоль как злокачественную, то такое предсказание является ложным положительным (false positive). Точно также, ложным отрицательным (false negative) является неправильное предсказание, что опухоль доброкачественная и истинным отрицательным (true negative) является правильное предсказание, что опухоль доброкачественная. Эти четыре результата могут быть использованы для расчета нескольких общих мер эфффективности классификации, включая погрешность (accuracy), точность (precision) и полноту (recall).
Погрешность вычисляется по следующей формуле:
![\[ACC=\frac{TP+TN}{TP+TN+FP+FN}\]](https://quicklatex.com/cache3/0b/ql_55152297dd20d50c7443ec64d5e6470b_l3.png "Rendered by QuickLaTeX.com")
где  — число true positive,
— число true positive,  — число true negative,
— число true negative,  — число false positive и
— число false positive и  — число false negative результатов.
— число false negative результатов.
Точность представляет долю опухолей, которые были предсказаны как злокачественные от фактического числа злокачественных опухолей. Точность вычисляется по следующей формуле:
![\[P=\frac{TP}{TP+FP}\]](https://quicklatex.com/cache3/05/ql_88671125cadcc5b98cd0201acc681105_l3.png "Rendered by QuickLaTeX.com")
Полнота - это часть злокачественных опухолей, которая определена системой. Полнота вычисляется по следующей формуле:
![\[R=\frac{TP}{TP+FN}\]](https://quicklatex.com/cache3/8d/ql_5ec5ebf39b667aa7a426918407e3a28d_l3.png "Rendered by QuickLaTeX.com")
В этом примере, точность определяет долю опухолей, которые были предсказаны как злокачественные от реального числа злокачественных. Полнота измеряет долю на самом деле злокачественных опухолей, которые были обнаружены.
Меры точность и полнота могли бы показать, что классификатор с впечатляющей погрешностью фактически не сможет обнаружить большинство злокачественных опухолей. Если большинство опухолей являются доброкачественными, то классификатор, который никогда не предсказывает злокачественных может иметь большую погрешность. Другой классификатор с меньшей погрешностью и большей полнотой, может лучше подойти для этой задачи, так как он будет определять больше злокачественных опухолей.
[add_ratings]
Еще по этой теме
 Робот Watch-Bot помогает рассеянным людям
Робот Watch-Bot помогает рассеянным людям AlphaGo обыгрывает чемпионов
AlphaGo обыгрывает чемпионов Google предоставляет API сервиса Cloud Vision для всех разработчиков
Google предоставляет API сервиса Cloud Vision для всех разработчиков Новый детектор пешеходов от Google поможет сделать самоуправляемые автомобили дешевыми
Новый детектор пешеходов от Google поможет сделать самоуправляемые автомобили дешевыми Компьютеры впервые выиграли в покер
Компьютеры впервые выиграли в покер Обучающая выборка и тестовые данные
Обучающая выборка и тестовые данные Язык программирования Python и пакеты для машинного обучения и Data Mining
Язык программирования Python и пакеты для машинного обучения и Data Mining Новая компьютерная программа сама познает мир
Новая компьютерная программа сама познает мир Задачи машинного обучения — ищем закономерности и предсказываем будущее
Задачи машинного обучения — ищем закономерности и предсказываем будущее Обработка информации в робототехнике
Обработка информации в робототехнике