Продолжаю публикацию материалов, посвященных алгоритмам, применяемым в робототехнике. В предыдущей статье я рассмотрел проблемы, которые могут встретиться при обработке различных данных, используемых роботами. Я также упомянул, что для решения этих проблем мы можем использовать алгоритмы машинного обучения либо инструменты вероятностного рассуждения. Сегодня речь пойдет о машинном обучении.
Задача регрессии
Используя регрессионный анализ мы можем найти зависимость одной переменной от другой путем «подгонки» имеющихся опытных данных некоторой функцией. Например, робот-футболист фиксирует положение мяча, через определенные моменты времени, то есть мы имеем некоторый дискретный набор значений. При этом, наши данные включают некоторую «шумовую» составляющую (этот шум может вносить наш датчик, например, видеокамера робота). И задачей является определить траекторию движения мяча и, зная ее, предсказать его положение в некоторый момент времени в будущем, на основе чего уже сформировать стратегию поведения робота.
Это задача решается методами обучения с учителем.
Задачи, которые мы пытаемся решить:
- Найти лучшую кривую(функцию) для подгонки уже имеющихся данных;
- Предсказать значение функции для новой точки данных (если имеющиеся данные представляют из себя временной ряд, как в случае с мячом, то, по-сути, нам нужно предсказать где же в будущем окажется этот мяч)
Более формально:
- Пусть X набор данных (в нашем случае — некоторые точки на оси времени)
- Предположим, что y - соответствующие им значения (координаты мяча)
- Необходимо найти такую функцию f что f (X) ≈ y
точки во времени X → f (X) → координаты мяча y
- Используя найденную функцию f, найти значение y для нового X (определить положение мяча в некоторый момент в будущем)
- Оценить качество полученного результата (насколько близко оказалось фактическое положение мяча по-отношению к предсказанному)
Выбор функции f (X) является достаточно сложной задачей, и вот почему. Если представить нашу функцию, которую называю целевой в виде полинома, то увеличивая степень этого полинома, мы сможем все лучше и лучше описать наши данные, полученные в прошлом. На картинке я показал пример подгонки точек данных линейной, квадратичной и кубическими функциями.
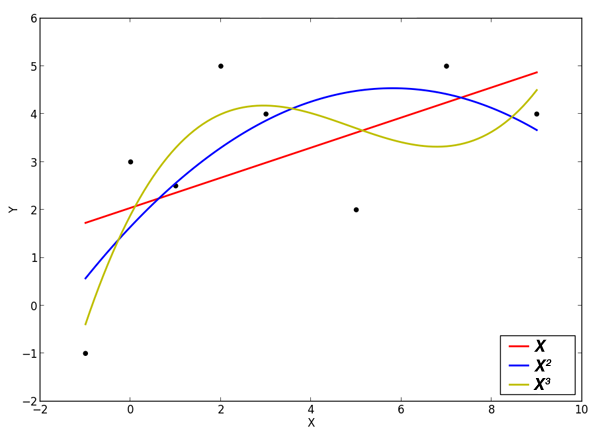
Увеличивая степень полинома, в какой-то момент можно достичь того, что все наши данные попадут на кривую, описываемую функцией f (X).
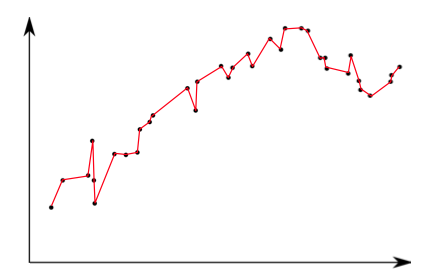
В этом случае возникает две проблемы. Первая — мы получили сложную модель (функцию). Вторая — полученная модель плохо обобщает, то есть она очень хорошо описывает данные, полученные в прошлом, но при использовании ее в предсказании, она, как правило, дает достаточно большую ошибку. Это, так называемая, проблема «переподгонки данных» или «переобучения».
Очень часто при решении регрессионных задач применяется линейная регрессия, когда в качестве функции, которой мы пытаемся подогнать наши данные выступает обычная прямая (линейная функция).
Задача кластеризации
Следующая группа задач, которую позволяют решать алгоритмы машинного обучения — это задачи кластеризации.
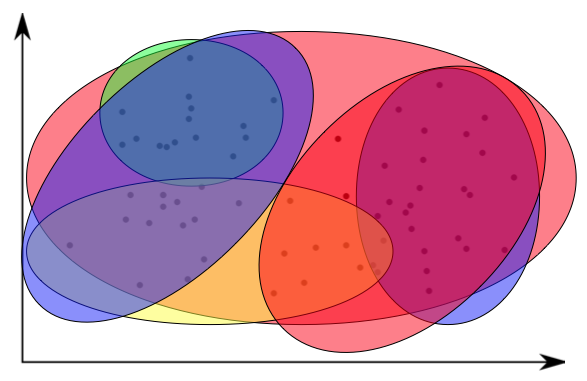
Это пример обучения без учителя.
Мы пытаемся:
- Выделить некие общности (кластеры) в имеющихся данных, другими словами, хоти сгруппировать данные в классы, которые нам изначально неизвестны.
- Предсказать к какому из полученных классов относится новая точка данных
Более формально:
- Пусть X — набор точек данных;
- Необходимо выделить набор классов K
- Найти связь между X и k.
Вариантов, как объединять имеющиеся данные может быть множество (см. рисунок выше).
Для решения этой задачи часто применяют алгоритм k-means (k-средних) и алгоритм для нахождения оценок максимального правдоподобия, или EM-алгоритм (Expectation Maximization algorithm).
Задача классификации
Представьте, что у нас есть набор данных и мы может отнести точку данных к тому или иному классу (например «свой» - «чужой»). Теперь у нас появляется новое значение и нам нужно определить «свой» это или «чужой». Задачей алгоритма будет найти какие же именно значения позволяют относить данные к тому или иному класcу.
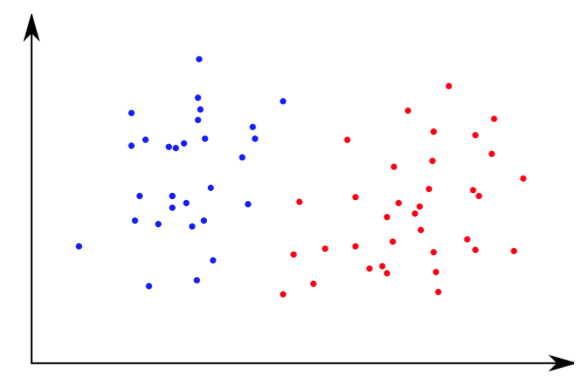
Нам нужно:
- Сгруппировать точки данных в известные классы
- Предсказать класс для новой точки данных
Формулировка:
- Пусть X - набор точек данных
- Пусть k — соответсвующий им класс
- Необходимо найти связь между X и k
- Найти k для нового X
- Оценить результат
Эта задача, как и задача регрессии решается методами обучения с учителем, так как нам известны целевые значения (или результаты испытаний).
Для решения этой задачи часто примяются алгоритм под названием «Машины опорных векторов» (SVM — Support Vector Machines), а также анализ главных компонент (PCA — Principal Components Analysis)
Оценка результатов обучения
Для оценки алгоритмов:
- Сравнивают различные модели
В случае регрессии мы можем сравнивать модели, использующие различные базисные функции, в случае классификации это могут быть различные формы кривых, определяющих классы
- Производят перекрестную проверку (cross-validation)
- Выбрать часть имеющихся данных (так называемое тренировочное множество)
- Оптимизировать модель на этих данных
- Взять другой набор данных, называемый тестовым множеством
- Оценить результаты работы модели уже на тестовом множестве
- Повторить пункты 1-4 несколько раз
- Если ошибка модели не сильно отличается в зависимости от выбранного множества, значит, как говорят статистики, модель является статистически значимой
В следующей публикации, посвященной алгоритмам, используемым в робототехнике я планирую рассказать про вероятностное рассуждение.
[add_ratings]
Еще по этой теме
 Робот Watch-Bot помогает рассеянным людям
Робот Watch-Bot помогает рассеянным людям AlphaGo обыгрывает чемпионов
AlphaGo обыгрывает чемпионов Google предоставляет API сервиса Cloud Vision для всех разработчиков
Google предоставляет API сервиса Cloud Vision для всех разработчиков Новый детектор пешеходов от Google поможет сделать самоуправляемые автомобили дешевыми
Новый детектор пешеходов от Google поможет сделать самоуправляемые автомобили дешевыми Показатели эффективности, смещение и дисперсия алгоритмов машинного обучения
Показатели эффективности, смещение и дисперсия алгоритмов машинного обучения Компьютеры впервые выиграли в покер
Компьютеры впервые выиграли в покер Обучающая выборка и тестовые данные
Обучающая выборка и тестовые данные Язык программирования Python и пакеты для машинного обучения и Data Mining
Язык программирования Python и пакеты для машинного обучения и Data Mining Новая компьютерная программа сама познает мир
Новая компьютерная программа сама познает мир Обработка информации в робототехнике
Обработка информации в робототехнике
Не совсем понял переход от футбола к полиномам. И в чем тут задача обучения. Скажем если б я решал бы задачу игры в футбол для робота я бы мыслил так:
1. Футбольное поле это плоскость из однородного материала.
2. Мы находим мяч. И отлслеживаем его.
3. Оценив положение мяча в момент его обнаружения и скажем через секунду мы можем построить вектор движения мяча.
4. Оценив положение мяча еще через секунду мы можем предсказать какая скорость мяча будет в каждой точке его траектории.
Соотвественно нам остается построить вектор нашего движения зная скорость самого робота так чтобы он оказался на пути мяча.
Мне кажется именно для такой задачки самообучающийся алгоритм был бы не нужен. Он занимал бы слишком много времени. Друго дело когда играет команда. Тут можно применять алгоритмы обучения для реализации действий всей команды. Определения кто именно будет перехватывать мяч. И как противостоять команде соперника.
Вы исходите из предположения, что ВСЕГДА определяете ТОЧНОЕ местоположение мяча. Это не так. Ваш измеритель всегда имеет погрешность, поэтому вы реально определяете координату с некоторой ошибкой. После каждого измерения у вас будет истинное положение мяча + ошибка. Если отобразить считанные значения с вашего датчика, то у вас вместо гладкой кривой (траектории, по которой реально летит мяч) получится набор точек, разбросанный вблизи вашей траектории. Задачей является нахождение этой гладкой кривой (без погрешности, или еще эту погрешность можно рассматривать как некоторый шум). А уже зная функцию, описывающую эту гладкую кривую (в ней уже учтено направление и сила ветра, коэффициент сопротивления среды, ее неоднородность и прочий миллион параметров, которые могут быть нестационарными), вы и предсказываете координаты мяча в следующий момент времени. Здесь можно применять различные подходы. Можно использовать различные виды регрессии, можно использовать вероятностный Байесовский подход. В радиолокации для определения координат летящих целей уже больше чем полвека используются фильтр Калмана (с кучей разновидностей), частичный фильтр, которые являются примерами методов второго подхода.
Обобщу. Любое полученное значение с измерителя нужно рассматривать как истинное значение измеряемой величины + погрешность измерения. Задача — определить истинное значение (не зная того, где вы сейчас находитесь, вы не можете знать, где вы окажетесь). Этот же вероятностный подход используется во многих узлах различных беспилотных мобильных роботов. В общем, датчик — всегда ВРЕТ, а для прогноза нам нужна ИСТИНА, иначе прогноз будет брехливым.
С командой вы совершенно правы.
Не буду спорить. Я пока не дошел до этого момента в своем проекте. Я пока только с механикой закончил. Но если рассуждать чисто эмпирически скажем датчики дистанции на основе ультразвука или инфракрасного излучения выдают погрешность и периодически дают неверный результат, который отсеивается на основе предыдущих и последующих показаний. А если говорить про камеру то возникает вопрос, какая ошибка тут может возникнуть? У нас есть снимок. Нам с точностью до милисекунды известно в какой момент времени он был сделан. Нам точно известно сколько в настоящий момент прошло времени с момента снимка. И проанализировав положение мяча на снимке и сопоставив его с моделью поля как мне кажется мы без всяких ошибок можем сказать где он будет в следующий момент. Конечно это верно если поле находиться в закрытом помещении и тут нет влияния ветра и прочего.
И еще можете подробнее обьяснить процедуру подборки полинома? Скажем на примере приведенного вами графика. Тут же дело не только в степени полинома тут и вопрос с коффициентами.
Погрешность камеры дает ее матрица, скорость затвора и нестационарность условий съемки (угол преломления электромагнитной волны (света) меняется в зависимости от коэффициента преломления среды). Высокоскоростная камера с большой разрешающей способностью даст, конечно, небольшую погрешность и все методы направлены на увеличение точности и снижения неопределенности. Если у вас измеритель, который дает точность, достаточную для предсказания с высокой достоверностью, условия измерений стационарны и вам известен аналитический вид уравнения движения, то, конечно, городить огород из сложных методов смысла нет, просто измеряйте и, на основе измерений, по известным формулам, делайте расчет.
Алгоритмы машинного обучения имеют смысл только, когда вам не известны все значимые факторы, влияющие на конечный результат, вам не известен аналитический вид каких-то зависимостей, или ваши данные тоже имеют ошибки/погрешности. Если все точно и все известно, просто пишете программный код, в котором берутся входные данные, подставляются в известную формулу и получаете результат в котором можете быть уверены.
Вы еще один момент не учитываете. Камера установлена где? На роботе? Тогда, какова точность определения местоположения самой камеры? Если же у вас супер точный измеритель, который жестко закреплен и неподвижен, все влияющие на результат параметры стационарны, вам известна точная формула, в которую нужно просто подставить параметры, то на выходе вы получите то, что вам и нужно. Здесь не нужны никакие data mining, machine learning. Просто такая идилия бывает не всегда и не везде.
Полиномы подбираются перебором. Вам нужно найти функцию, которая аппроксимирует ваш набор данных наилучшим образом с точки зрения какого-нибудь критерия. Далее выбирается критерий оптимальности для вашей функции, который минимизируется (максимизируется). Например, метод наименьших квадратов (минимизация среднеквадратичной ошибки) или метод максимального правдоподобия. Далее, ищутся параметры (коэффициенты перед полиномиальными членами и степени полинома) для которых этот критерий выполняется. Здесь используются различные методы оптимизации (для выпуклых функций, например, это может быть метод градиентного спуска). Все эти методы зачастую требуют больших вычислительных возможностей, поэтому активно широко стали применяться буквально только-только (компьютеры стали мощными и дешевыми).
Я планирую подробно в дальнейшем на своем блоге рассматривать различные методы и алгоритмы, но все они сводятся в двух словах к следующему. У вас есть какой-то набор данных (вход) и есть какой-то желаемый результат (выход). Например, результаты каких-то достоверных экспериментов. Вы не знаете закон природы, по которому, имея входные данные, вы получаете выходные. Для вас этот закон природы — «черный ящик». Задача алгоритмов ML, DataMining соорудить для вас этот черный ящик. Компьютер пытается подобрать закономерность, которая из входа делает выход (и эта закономерность, помимо того, что отлично работает уже на известных вам парах вход-выход, но еще и формирует правильный выход для ранее вам неизвестного входа). Если устройство черного ящика вам хорошо известно (известен закон природы), то счастье у вас уже есть, вам больше ничего не нужно.
Причем тут скорость затвора? Зачем нам фотоаппарат? Насколько я понимаю у современной скажем веб-и камеры в момент работы затвор постоянно открыт. Соотвственно картинкаэто просто массив данных с пикселей матрицы на момент времени т1. Далее если у нас на роботе закреплено 2 камеры на известном расстоянии друг от друга мы получаем стереоскопическое зрение позволяющее простейшими математическими операциями вычислить дистанцию до любого объекта. А распознать мячик как круглый скажем красный объект задействовав например библиотеку OpenCV не состтавит труда,
Про затвор я, наверное, не совсем правильно выразился. Я имел ввиду число кадров в секунду. Если кадров мало, то у вас получается меньшее число точек данных и тем большую погрешность в вычислении скорости вы имеете.
Как и любое цифровое устройство, современные фото-видео камеры подвержены ошибкам «квантования по уровню». У вас есть ограниченное число линий по вертикали (например, 240). Если вы снимаете объект размером 2 метра, который занял весь кадр, то погрешность определения координаты Y каждой точки по снимку у вас составит как минимум 2000/240/2= 4.2 мм.
Матрица вашей камеры имеет ограниченное разрешение. Вот для примера. Представьте снимок футбольного поля сверху камерой, делающий снимок с разрешением 320×240 пикселей и 4000×3000 пикселей. В каком случае вы сможете точнее определить координату мяча? Microsoft Kineсt определяет координаты имея камеру с разрешением, скорее всего 320×240 пикселей (по-крайней мере первые модели), правда для опеределения глубины там имеется инфракрасный датчик. При этом удается получить точность определения координат порядка нескольких сантиметров при удалении от устройства до 7м. Для каких-то задач этой точности вполне достаточно, для каких-то нет.
Расположив две камеры на роботе, вы сможете с какой-то точностью определить расстояние до объекта ОТНОСИТЕЛЬНО робота, а точнее той его точки, в которой установлены камеры. А насколько точно вам известны абсолютные координаты робота в неподвижной системе координат, скажем относительно ворот?
Вы привели в качестве примера библиотеку ОpenCV, которая распознает образы. В ней очень широко используются алгоритмы машинного обучения: расстояние Махаланобиса, k-средних, Байесовский классификатор, решающие деревья, бустинг, случайный лес, классификатор Хаара, максимизация ожидания, k-ближайших соседей, машины опорных векторов. Для задач распознавания образов широко применяются нейронные сети. Если вы не руками реализуете какой-то алгоритм, это совсем не означает, что он не используется уже в готовом, применяемом вами устройстве/программе.