
В предыдущей статье я разбирал что же такое машинное обучение и Data Mining. Сегодня я хочу поговорить об основных группах алгоритмов машинного обучения.
Напомню, что мы используем машинное обучение тогда, когда мы не знаем как конкретно описать алгоритм для решения некоторой задачи. Если же алгоритм нам известен заранее и мы можем его формализовать, то мы просто переносим свое решение в программный код.
Например, к таким задачам машинного обучения относятся создание беспилотного автомобиля, распознавание рукописного текста, задачи обработки естественного языка (NLP — Natural Language Processing), компьютерное зрение (Computer Vision). Некоторые из этих задач мы с вами решаем повседневно, но описать их решение путем последовательной записи компьютерных команд не представляется возможным. Мы успешно читаем рукописный текст людей, имеющих свой способ написания той или иной буквы, иногда даже понимаем что пишут врачи 🙂

Но мы сами четко не понимаем каким образом мы это делаем, как наш головной мозг деалет это. Вот для решения задач в подобных случаях и применяются алгоритмы машинного обучения.
Выделяют два основных класса алгоритмов машинного обучения — это обучение с учителем (supervised learning) и обучение без учителя (unsupervised learning). Отмечу, что кроме этих классов выделяют также алгоритмы обучения с подкреплением (reinforcement learning) и рекомендательные системы (recommender systems). Пример рекомендательной системы вы можете видеть после каждой статьи на моем блоге (и эта статья не является исключением), где вам предлагаются схожие по тематике статьи под заголовком «Еще по этой теме».
Обучение с учителем
Как следует из названия, для работы этого типа алгоритмов нам потребуется «учитель», который и будет «учить» наш алгоритм. Так каким же образом происходит обучение алгоритма? Попробую разобрать это на простом примере.
Давайте представим процесс принятия решение в виде некоторого «черного ящика», который непонятно как работает внутри, для нас важен только результат его работы.

Рассмотрим это на примере задачи распознавания образов в которой нам нужно определить, относится некоторый объект к автомобилям или нет.
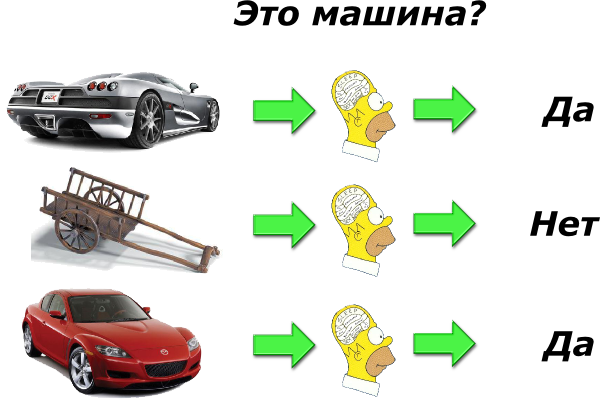
В данном случае мы выступаем в качестве эксперта, который формирует так называемое «обучающее множество», т.е. набор примеров и правильных ответов с экспертной точки зрения. Далее мы передаем, или как говорят, «скармливаем» полученное множество с набором примеров, которые обозначим как X и решений, которые обозначим как Y в некий алгоритм, задачей которого найти некоторую функцию f (X), преобразующую множество X в множество Y
X → f (X) → Y
Такие пары множеств примеров и решений еще называют парами объект — ответ, или прецедентами. Процесс обучения с учителем также часто называют процессом обучения по прецедентам.
Далее, используя найденную функцию, наш алгоритм пытается найти ответ для примера, которого не было в обучающем множестве.

Согласитесь, это непросто решить даже для эксперта 🙂
Вот, в двух словах как работает обучение по прецедентам. Я в последующих статьях еще неоднократно буду возвращаться к алгоритмам обучения с учителем. Сегодня я просто хотел бы дать самое общее представление о том, что это такое.
Обучение без учителя
В этом случае, как следует из названия, алгоритмам приходится обучаться самостоятельно.
Приведу пример. Если у вас есть своя страничка в социальной сети, то наверняка, есть и какие-то «друзья», как-то с вами связанные. У этих друзей есть свои друзья и так далее.
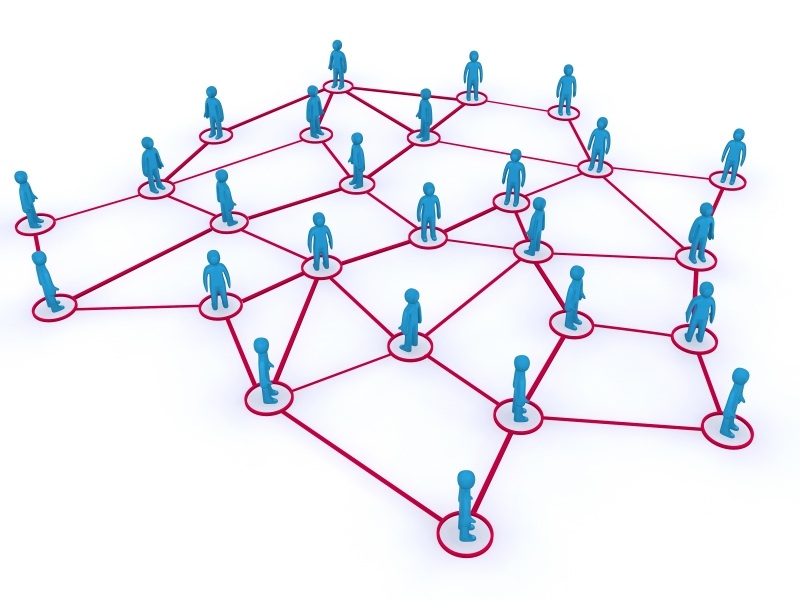
Имея схему взаимосвязей и некоторую информацию по всем этим людям, возможно выявить какие-то общности которые всех их связывают. Это могут быть, например, общие учебные заведения, место проживания, общие онлайн игры в которые эти люди играют, общие интересы и прочее. То есть мы можем выделить некоторые общности, или группы, или, как еще их называют, кластеры, о которых мы даже и не догадывались, соответственно и не могли обучить их нахождению свой алгоритм.
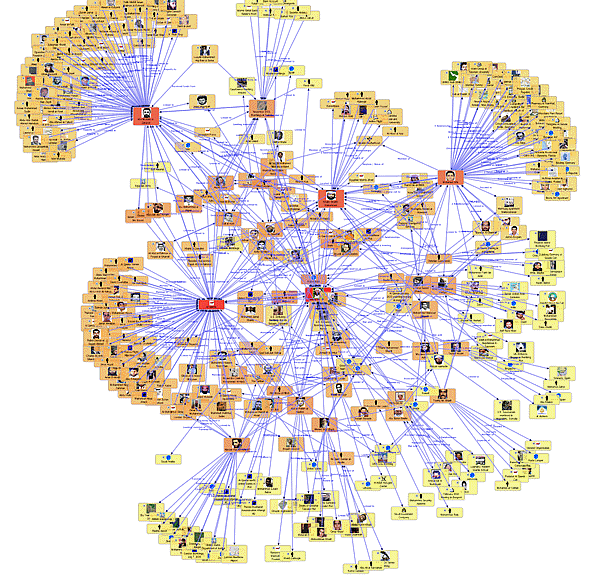
Такая задача называется задачей кластеризации. В таком типе задач требуется обнаружить некоторые внутренние связи, зависимости, закономерности, которые существуют между исследуемыми объектами.
Такие вопросы часто возникают в маркетинге, где требуется выделить какие-то сегменты рынков, целевые группы потребителей, в исследованиях астрономических данных, при организации компьютерных кластеров.
Более детально я рассмотрю класс алгоритмов с обучением без учителя в последующих своих публикациях.
На сегодня у меня все. Как обычно, буду рад вашим вопросам.

 (12 голосов, средняя оценка: 4,08 из 5)
(12 голосов, средняя оценка: 4,08 из 5)Еще по этой теме
 Что такое Машинное обучение и Data Mining
Что такое Машинное обучение и Data Mining Обработка информации в робототехнике
Обработка информации в робототехнике Как это работает: беспилотный автомобиль Google
Как это работает: беспилотный автомобиль Google Идея и шасси моего мобильного робота
Идея и шасси моего мобильного робота  Робот Watch-Bot помогает рассеянным людям
Робот Watch-Bot помогает рассеянным людям AlphaGo обыгрывает чемпионов
AlphaGo обыгрывает чемпионов Google предоставляет API сервиса Cloud Vision для всех разработчиков
Google предоставляет API сервиса Cloud Vision для всех разработчиков Новый детектор пешеходов от Google поможет сделать самоуправляемые автомобили дешевыми
Новый детектор пешеходов от Google поможет сделать самоуправляемые автомобили дешевыми Показатели эффективности, смещение и дисперсия алгоритмов машинного обучения
Показатели эффективности, смещение и дисперсия алгоритмов машинного обучения Компьютеры впервые выиграли в покер
Компьютеры впервые выиграли в покер
К сожалению, текущая стадия развития обучающихся алгоритмов не настолько хороша — они работают только в узко ограниченных рамках одной проблемы. Наверное, в этом смысле термин «обучение» скорее означает «способность решить уравнение на основе предоставляемых данных».